You can create a Scheduler job from:
- Projects or Project Groups—refer to Building Scheduler Jobs from Projects or Groups for details.
- Object Groups—refer to Building Scheduler Jobs from Object Groups for details.
- Diagrams—refer to Creating a Job from a Diagram for details.
Click the Scheduler tab to open the Scheduler window.

Click the New Job button to create a new job.

A Job Definition window is displayed.
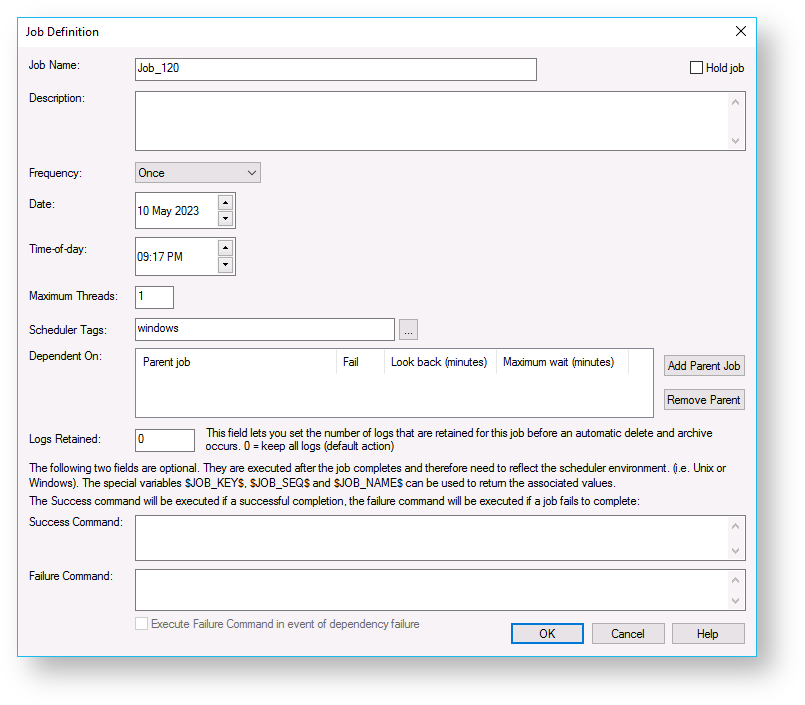
Complete the fields and then click OK. The main fields are described in the following table:
| Field | Description |
|---|---|
| Job Name | The Scheduler defaults to the next job number in the sequence. You can alter this to any alphanumeric. Only alphanumerics, spaces, and the underscore are supported in the name. On some UNIX systems, long job names can cause jobs to be canceled (see Knowledge Base article 67), so where possible keep the name short. |
| Description | A description of the job. |
| Frequency | When the job runs. The options available in the drop-down list box are:
|
| Start Date and Start Time | The date and time for the job to start. |
| Max Threads | The maximum number of threads allocated to run the job, e.g., if some tasks can run in parallel then if more than one thread is allocated they will run in parallel. |
| Scheduler | Certain types of jobs will only run in a specific environment. For example, ODBC-based loads can only be handled by the Windows scheduler. It is possible to have multiple schedulers running. Select the desired scheduler from this drop-down. The valid options are: UNIX Preferred, UNIX Only, Windows Preferred, Windows Only, or the name of a specific scheduler can be entered (e.g. WIN0002) |
| Dependent On | A job can be dependent on the successful completion of one or more other jobs. Click the Add Parent Job button to select a job that this job will be dependent on. The maximum time to look back for parent job completion field prevents older iterations of the parent job as being identified as a completion. The maximum time to wait specifies how long to await a successful completion of the parent job. The action if that wait expires can also be set. Refer to the Job Dependency example in Scheduling a Job for details. |
| Logs Retained | Specify the number of logs to retain for the job. By default, all logs are retained. This field can be used to reduce the build-up of scheduler logs by specifying the number of logs to retain. |
| Success command and Failure command | These are either UNIX or Windows shell commands depending on which scheduler is used. They are executed if the condition is met. Typically, these commands would mail or page on success or failure.
|
The following fields are available if a frequency of Custom is chosen:
| Field | Description |
|---|---|
| Interval between jobs (Minutes) | Specify the number of minutes between iterations of the job. For example, to run a job every 30 minutes set this value to 30. If a job is to run only once but on selected days set this value to 1440 (daily) |
| Start at or after HHMM | The time that the job may run from. To run anytime set to 0000. |
| Do not start after HHMM | If multiple iterations are being done then this is the time after which a new iteration will not be started. For example, if a job is running every 10 minutes it will continue until this time is reached. To run till the end of day set to 2400. |
| Active on the days | Select each day of the week that the custom job is to be active. |
Once the job itself has been defined, tasks then need to be added to the job. The Define tasks window is shown below.

The screen has two main areas. The right pane shows the tasks to be run for this job and the left pane lists all the objects.
Adding a task
Double-click an object in the left pane to add it to the task list in the right pane. Normally objects, such as Load or Fact tables are scheduled rather than procedures.
Setting the action on a task
Each task can have a specific action that is to be performed on its object.
The default action for load tables is process. This means that when the task is actioned, it will drop any indexes that are due to be dropped, or have pre-drop set, then load the table and perform any post-load procedures or transformations and then re-create any dropped indexes.
The default action for all other tables is the same as above, except it will execute the update procedure rather than loading the table.
You can change the action on a task by right-clicking the task in the right pane. The menu options are shown below.

The following task actions are available:
Setting the state of a task
Each task can be set to a state:

The following states are available:
State | Description |
|---|---|
Enable | Job Task is enabled. |
Disable | Job Task is disabled. |
Disable Once | Job Task is disabled once and then reverts to enabled next time the Job is released by the Scheduler. |
Creating dependencies between tasks
You can create dependencies between tasks in the list by selecting one or more tasks and right-clicking to bring up the dependency options.

The following task dependency options are available from the menu:
Task Option | Description |
|---|---|
Group Selected Tasks | Groups two or more selected tasks to have the same order value, allowing them to run in parallel if the maximum threads setting allows. |
Ungroup Selected Tasks | Un-group selected tasks. |
Sync with Item Above | Changes a selected task to have the same order value as the task above it, allowing them to run in parallel if the maximum threads setting allows. |
Sync with Item Below | Changes a selected task to have the same order value as the task below it, allowing them to run in parallel if the maximum threads setting allows. |
Decrease the Order | Changes a selected task to an order number one less than its current value. The task will now run immediately before it would have previously. |
Increase the Order | Changes a selected task to an order number one more than its current value. The task will now run immediately after it would have previously. |
Ordering or Grouping the tasks
The Order column shows the order in which the tasks are to be run, e.g. 20.20 If the two numbers are the same as another task then those tasks can run in parallel. If the two numbers are different then those tasks run sequentially. This is an initial definition of dependencies. These dependencies can be altered specifically once the job has been created.
Tasks can be moved up or down by selecting the task and clicking the Move Up ![]() or Move Down
or Move Down ![]() buttons.
buttons.
To respace the order of the tasks; to group or ungroup object types, use the buttons at the bottom of the Define tasks window.

Button | Description |
|---|---|
Respace Order | Click to respace the order numbers. The existing dependency structure and groupings are retained. The purpose of this button is simply to allow room between tasks to fit new tasks. For example, if we have two tasks that have an order of 20.19.5 and 20.20.6 and we want to add a task between these two tasks, we can click the Respace Order button to open up a gap between the two tasks. |
Group Object Types | Click to put all objects of the same type into groups. For example, all load tables will be able to run in parallel, all dimensions, etc. |
Ungroup All | Click to remove all groupings and make all tasks sequential. New groupings can be made by selecting a range of sequentially listed tasks in the left pane and using the right-click menu option Group Selected Tasks. Tasks that are grouped have the same first two numbers in the order and can execute at the same time if the job has multiple threads. |
Upon completion of adding tasks, click OK to exit.