Page History
...
Table 12-81 Heavy Index Overhead
...
| Description |
|---|
| What to do |
...
| next | Perform one of the following options: |
...
|
...
|
...
|
...
|
...
|
...
| Advice | Perform one of the following options: |
...
|
...
The Statements tab shows the activity and execution plans that were detected during the selected time frame and may not reflect the activity of all the statements and execution plans executed during this time frame. Proceed with caution when determining whether to drop an index or delete a column from an index. |
| Example |
...
Table: INSERTED_TABLE (C1 number,C2 date, C3 varchar2(128), C4 number) Indexes on table: IX1 (C1,C2) IX2(C4,C3) Statement: Insert into INSERTED_TABLE values (:h1,:h2,:h3,:h4) In this example, Oracle fetches the relevant index blocks of the two indexes, for the new rows, even though the indexes do not appear in the execution plan. The I/O wait accumulated while fetching these index blocks is considered to be an index update. |
| Anchor | ||||
|---|---|---|---|---|
|
...
Table 12-82 Extensive Full Table Scan Access
...
| Description |
|---|
| What to do |
...
| next | Perform the following options: |
...
|
...
|
...
|
| Advice |
...
Perform one of the following options: |
...
|
...
|
| Anchor | ||||
|---|---|---|---|---|
|
...
Table 12-83 Full Scan Reading Deleted Blocks
...
| Description |
|---|
| What to do |
...
| next | Perform the following options: |
...
|
...
|
| Advice |
...
Perform one or more of the following options: |
...
|
...
|
...
|
| Anchor | ||||
|---|---|---|---|---|
|
...
Table 12-84 Index Clustering Factor Very High
...
| Description |
|---|
| What to do |
...
| next | Perform the following options: |
...
|
...
|
| Advice |
...
Perform one of the following options: |
...
|
...
|
The following example shows the effect that a bad clustered index can have on performance when an index is scanned:
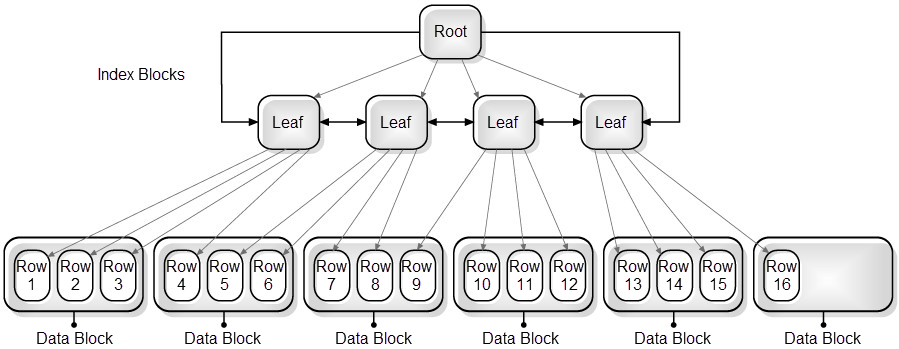
The figure below shows an example of an index with a good clustering factor. In this example, the root is read first, followed by the first leaf page. Then the first data block that serves the first three keys matching the three rows in the data block is fetched. In this way the keys and data blocks that follow are read. The I/O operations required by this scan include five index blocks and six data blocks, which is the equivalence of 11 I/O operations.
Figure 12-1 Index with good clustering factor (low = number of table blocks)
Root
Index B ocks
Leaf Leaf Leaf Leaf
Row Row Row
Row Row Row
Row Row Row
Row Row Row
Row Row Row
Row
1 2 3
4 5 6
7 8 9
10 11 12
13 14 15 16
Data B ock Data B ock Data B ock Data B ock Data B ock Data B ock
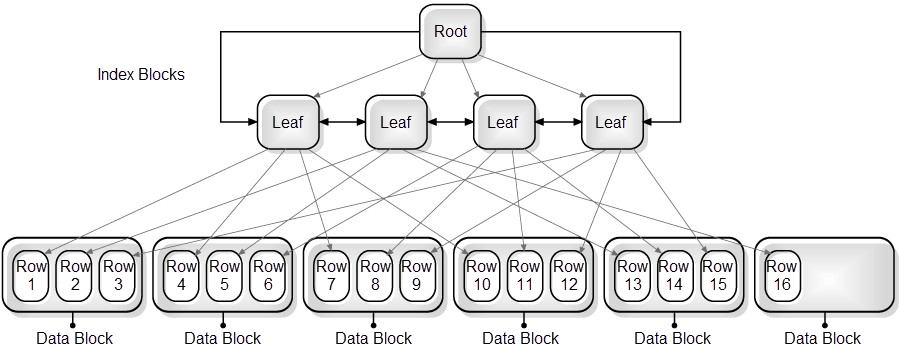
The following figure shows an example of an index with a bad clustering factor.
The index with the bad clustering factor starts in the same way as the index with the good clustering factor. However, when the second key in the index is read, the row for the second key in the first data block has not yet been fetched, so another block must be fetched. By the time Oracle accesses the index key matching the second row in the first table block, it has already been swapped out of memory and needs to be re-read. In the worse case scenario, I/O for the table blocks will be required for every index key. The I/O operations required by this scan include five index blocks and 16 table blocks, which is equivalence of 21 I/O operations. When the difference between the number of blocks and number of rows is great, performance can be greatly impacted.
Figure 12-2 Index with bad clustering factor (high = number of rows)
...
Root
Index B ocks
Leaf Leaf Leaf Leaf
Row Row Row
Row Row Row
Row Row Row
Row Row Row
Row Row Row
Row
1 2 3
4 5 6
7 8 9
10 11 12
13 14 15 16
Data B ock Data B ock Data B ock Data B ock Data B ock Data B ock
| Anchor | ||||
|---|---|---|---|---|
|
...